Elena Ivona Dumitrescu, Sullivan Hué, Christophe Hurlin & Sessi Tokpavi, 2022, European Journal of Operational Research, 297(3), 1178-1192
RESEARCH PROGRAM
Over the last decade, machine-learning developments have considerably modified traditional professional practices. Algorithm-based decisions are becoming dominant in many areas and the financial industry is no exception. Currently, for instance, credit scoring is being greatly impacted by machine-learning techniques. Historically, credit scoring relied on a simple logistic regression to discriminate between borrowers based on their credit-worthiness. But many recent studies have shown that sophisticated machine-learning algorithms achieve higher predictive performance and can improve measurement accuracy on borrowers’ default probability since, unlike the logistic regression, they automatically capture many complex non-linear relationships. However, one very important issue is their lack of explainability and interpretability. Indeed, most of these algorithms are considered to be “black boxes” because of the opacity of their underlying decision process. With cred it scoring, these algorithms lead to scorecards and credit approval processes that financial practitioners cannot easily explain to customers and regulators. Yet explainability is essential in credit-scoring models. This is currently the main weakness of such algorithms, limiting their use in the credit-scoring industry despite the accuracy of their predictions. Is it possible to develop a credit-scoring model combining the accuracy of machine learning algorithms with the interpretability needed by financial regulators? We show in this paper that an answer to this question comes from the combination of machine learning and econometrics.
PAPER’S CONTRIBUTION
This paper introduces a hybrid credit scoring approach called the Penalised Logistic Tree Regression model (PLTR), whose main objective is to avoid the tradeoff between performance and interpretability. More precisely, the model improves the predictive performance of the logistic regression model through data pre-processing and feature engineering based on machine-learning techniques. The model proceeds in two steps. The objective of the first step is to build new predictors from original variables. Formally, short-depth decision-trees of one split (two splits) are built for each original variable (couple of original variables) to capture endogenous univariate (bivariate) threshold effects. In the second step, the endogenous univariate and bivariate threshold effects are plugged into a logistic regression so as to increase its predictive performance. To prevent overfitting issues due to a potential high number of threshold effects, the model relies on an adaptive lasso penalisation for both estimation and variable.
This approach has several advantages. First, it makes the most of the main advantage of machine learning algorithms: it captures non-linear effects arising in credit-scoring data through short-depth decision trees, allowing the model to reach high predictive performance. Second, it addresses the lack of interpretability of machine-learning approaches by relying on econometrics, leading to an interpretable model as recommended by financial regulators. Finally, the approach can be viewed as a systematisation of common practices used in the industry. Credit risk modellers usually introduce non-linear effects into the logistic regression by using ad hoc or heuristic pre-treatments and feature engineering methods (discretisation of continuous variables, identification of non-linear effects with cross-product variables, etc.). In contrast, we propose a systematic and automatic approach for modelling unobserved non-linear effects based on short-depth decision trees.
We illustrate through Monte-Carlo experiments and empirical applications that the PLTR model predicts credit risk significantly better than the industry’s current benchmark model. Moreover, we show that the model compares competitively to state of-the-art machine-learning algorithms in terms of predictive performance while allowing a simple interpretation of the credit approval process. The scoring decision rules of the PLTR model remain easily interpretable and similar to those of the standard logistic regression. Finally, we show that the PLTR model is valuable from an economic perspective, as it generates large cost reductions compared to the industry’s benchmark credit-scoring model.
FUTURE RESEARCH
This paper proposes a way to avoid the tradeoff between performance and interpretability by combining econometrics and machine-learning algorithms. However, many other unanswered challenges to the use of machine-learning techniques in the credit-scoring industry could also be solved by this combined approach, such as the fairness of machine-learning algorithms. Indeed, black-box algorithms can systematically discriminate against a particular group of individuals, which is illegal in some cases but in any case perceived as unethical and detrimental to the reputation of the firms involved. A recent example is the Apple Pay app that discriminated against credit applications from women and led to major public criticism of Apple. A combination of econometrics and machine learning could be used to detect such unfair algorithm behaviour so as to prevent potential discrimination.
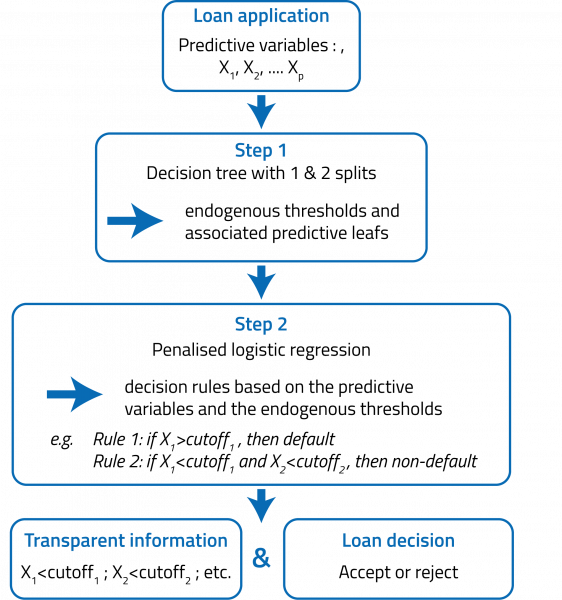
Figure 1. PLTR inference process
REFERENCE
Denant-Boemont, L., C. Gaigné, and R. Gaté (2018). “Urban spatial structure, transport-related emissions and welfare.” Journal of Environmental Economics and Management, 89, 29-45.
→ This article was issued in AMSE Newletter, Summer 2022.
© asiandelight on Adobe Stock